








MWC24巴塞罗马 中国企业闪耀创新力量
在伊比利亚半岛的明珠巴塞罗那,MWC24再次引爆了全球科技圈的沸腾热情。Fira Gran Via各大展馆水泄不通的人群似乎在传递着这样的信息:我们正迎来行业的又一个“春天”!而这样的新篇章将由5G与AI共同书写,并且,中国企业将在其中扮演重要角色。



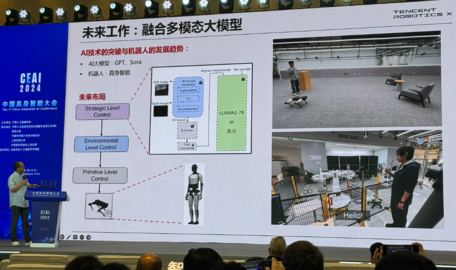
中兴通讯发布端到端算力基础设施解决方案 加速全行业数智化转型
在2024年MWC世界移动通信大会上,中兴通讯发布端到端算力基础设施解决方案,提供算/存/网/IDC完整的全套解决方案,实现全栈软硬件一体化部署,加快业务上云速度。























----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-